March 8, 2024
Open Source Strikes Bread - New Fluffy Embedding Model
And another one! We are excited to introduce our new and powerful embedding model. It comes with an Apache 2.0 license and is available on Hugging Face.
Read on to learn more about our approach and to check out our benchmarks. If you want to skip right to the model instead, you can access it here:
- mxbai-embed-large-v1: Strong, powerful, and large. But not too large.
TLDR:
Our English embedding model provides state-of-the-art performance among other efficiently sized models. It outperforms closed source models like OpenAI's text-embedding-v3.
Why Embeddings?
A significant hurdle for modern generative models is their inability to directly interact with your data. Consider a scenario where your task is to generate a report on recent market trends based on internal research documents. Traditional generative models fall short here as they don't have access to or understanding of your internal documents, making it impossible for them to generate the required report.

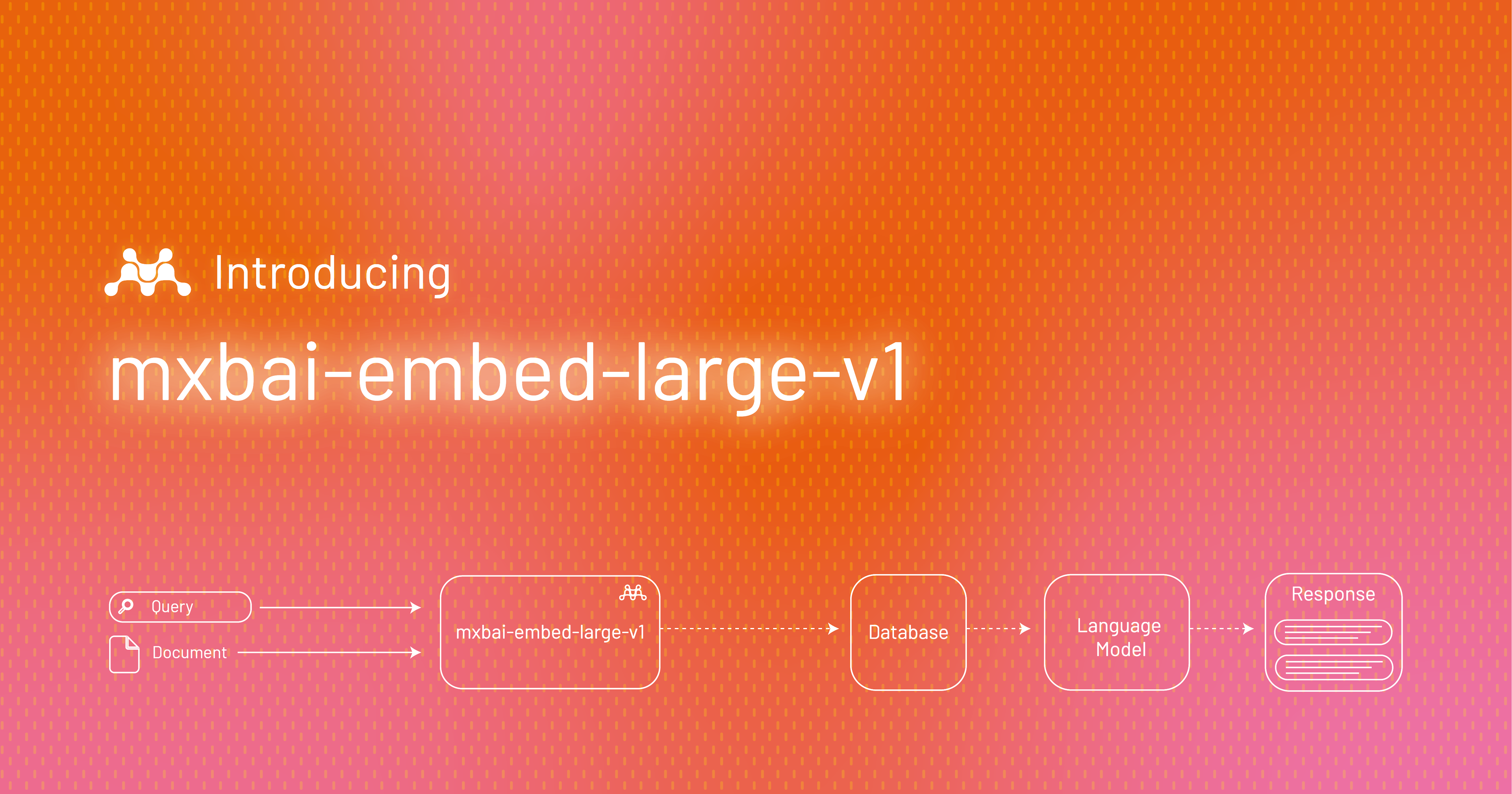
The process of Retrieval-Augmented Generation, powered by embeddings
To address this challenge, the Retrieval-Augmented Generation (RAG) technique offers a solution. Imagine you have a repository of internal research on market trends. This repository can be processed through an embedding model to convert the documents into a searchable format within a vector database. When you need a report on market trends, the embedding model can locate and fetch the most relevant documents. These documents can then inform a generative model, enabling it to produce a detailed report based on your specific data.
Introducing Our Powerful Embedding Model
Earlier this week, we ventured to the forefront of research into new ways of making embedding models more efficient with the release of our 2D-🪆 model, first of its kind.
Today, we want to return some of our attention to slightly more well-charted waters: we are releasing our flagship, state-of-the-art English embedding model, which can be easily downloaded into your existing search pipeline. No fancy custom code or trust remote code required.
As of March 2024, our model achieves state-of-the-art performance for open-source models of the same size class (for closed source models this information is not public) on the Massive Text Embedding Benchmark (MTEB).
Using It in Action
Our model is extremely easy to use with your existing search stack. You replace the first stage retrieval with our model, and you're ready to go. You’ll have two options: use the model either offline by hosting it yourself or online by using our (upcoming) API.
To get started, install the necessary packages:
Then, you can use the model like this:
The result will look like this:
Why Do We Need the Prompt?
The prompt improves the model's understanding of how the embedding will be used in subsequent tasks, which in turn increases the performance. For now, we support only one prompt, but our experiments show that having domain specific prompts can increase the performance. If you are doing information retrieval, please use the prompt Represent this sentence for searching relevant passages: for your query. For everything else, just use the text as it is.
Built for RAG and Real World Use-Cases
While a lot of models use ready-made datasets -- which are pretty outdated and also quite far removed from real world use cases -- we spent a lot of time building our own datasets. We scraped a large part of the internet, cleaned the data, and used it to construct our training dataset.
During the whole process, we ensured zero overlap with tests of MTEB. We went out of our way to not even use any training data from the MTEB (except MS Marco), unlike most other models. We trained our model with over 700 million pairs using contrastive training and tuned it on over 30 million high quality triplets using the AnglE loss. The vast amount and high quality of data ensures that the model has seen a lot of topics and domains, and that it performs well in real life and RAG-related use cases.
Model Evaluation with MTEB
MTEB is a large text embedding benchmark that measures embedding models across seven tasks: classification, clustering, pair classification, re-ranking, retrieval, STS (semantic textual similarity), and summarization. It includes 56 datasets from various domains and with various text lengths.
Our new model is ranked first among embedding models of similar size, outperforms the new OpenAI embedding model, text-embedding-3-large, and also matches the performance of 20x larger models like echo-mistral-7b. You can find the evaluation results on the official MTEB leaderboard.
PS: You can boost the performance even further by combining our embedding model with our rerank model.
| Model | Avg (56 datasets) | Classification (12 datasets) | Clustering (11 datasets) | PairClassification (3 datasets) | Reranking (4 datasets) | Retrieval (15 datasets) | STS (10 datasets) | Summarization (1 dataset) |
|---|---|---|---|---|---|---|---|---|
| mxbai-embed-large-v1 | 64.68 | 75.64 | 46.71 | 87.2 | 60.11 | 54.39 | 85.00 | 32.71 |
| bge-large-en-v1.5 | 64.23 | 75.97 | 46.08 | 87.12 | 60.03 | 54.29 | 83.11 | 31.61 |
| mxbai-embed-2d-large-v1 | 63.25 | 74.14 | 46.07 | 85.89 | 58.94 | 51.42 | 84.9 | 31.55 |
| nomic-embed-text-v1 | 62.39 | 74.12 | 43.91 | 85.15 | 55.69 | 52.81 | 82.06 | 30.08 |
| jina-embeddings-v2-base-en | 60.38 | 73.45 | 41.73 | 85.38 | 56.98 | 47.87 | 80.7 | 31.6 |
| Proprietary Models | ||||||||
| OpenAI text-embedding-3-large | 64.58 | 75.45 | 49.01 | 85.72 | 59.16 | 55.44 | 81.73 | 29.92 |
| Cohere embed-english-v3.0 | 64.47 | 76.49 | 47.43 | 85.84 | 58.01 | 55.00 | 82.62 | 30.18 |
| OpenAI text-embedding-ada-002 | 60.99 | 70.93 | 45.90 | 84.89 | 56.32 | 49.25 | 80.97 | 30.80 |
The results on MTEB show that our model performs well for a number of different tasks and domains. This means that the model can adapt to a plethora of use cases and topics, making it an obvious choice for users.
Unfortunately, many recently published embedding models were trained on the MTEB datasets, frequently even on the actual test sets (i.e., telling the model the correct answers for the test set, which is basically cheating). For our training, we excluded any potential overlap with the test sets by removing potential test candidates from the comparison.
Why No Long Context Length? Matryoshka? Preference?
Recently, we've observed that some models are advertised as supporting long context to mitigate chunking. While we recognize that chunking sucks, which is also something we are working to solve, using a long context model is not the solution.
With embeddings, we aim to capture the semantics of a text. For illustrative purposes, think of your own long context documents. They can contain any amount of different information and multiple topics which can be unrelated or contradictory. Accurately representing this with a single embedding is almost prohibitively difficult, which is why we decided not to support long context and to solve this issue in a smarter, more sensible way instead. Stay tuned, cool stuff is coming soon!
The same goes for 🪆 embeddings: we love the concept, as you can read in our blog post Fresh 2D-Matryoshka Embedding Model. A new version supporting 🪆 is in the making, as well as a version that fixes small issues regarding preference of the retrieved candidates -- we aim to close any potential performance gaps to commercial, closed-source models that our model, despite its extremely strong overall performance, might still face for specific tasks.
Give Us Feedback
This is our first production-ready embedding model, and we greatly welcome any feedback that helps make our models better, refine their user-friendliness, or improve their capabilities. Please let us know if you're hungry for any new features or have encountered any issues. We value your feedback!
Please share your feedback and thoughts through our discord community. We are here to help and also always happy to chat about the exciting field of machine learning!